
FIND OUT MORE
Want to know more about ProcessFlows Data Capture solutions? Contact us on:
+44 (0)1962 835053
How does OCR and ICR software know which data to extract from documents?
August 13, 2009You apply ‘rules’, and tell it what to do!
Malcolm Wilkes, ProcessFlows:
OCR (Optical Character recognition) and ICR (Intelligent Character Recognition) software ‘reads’ and extracts words and text from a document (paper or electronic) and then exports the data, along with the document, to another electronic system. This could be your everyday line of business system, a data storage or document management repository, or a contact database such as excel, access or SQL.
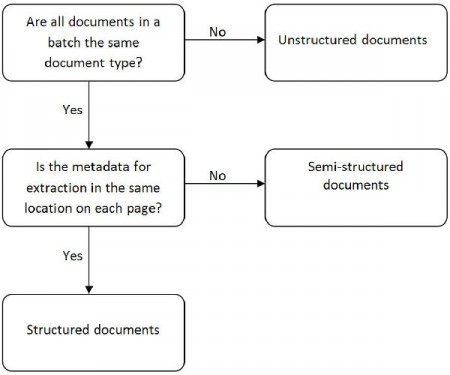
OCR extracts data from structured documents. ‘Intelligent’ and ‘thinking’ ICR technology is used when you need to extract information from the more challenging semi-structured and unstructured documents.
Depending on the types of documents you are trying to capture, rules are used to configure the extraction process.
Structured Documents
Example – Forms:
- OCR works well with forms because they are structured documents – the data is in the same place on each page
- You would setup a rule so that software only ‘looks’ in a specific location on the form
- You can also tell the software to ‘look’ for data in a regular expression. Expression example: the value will always be two alpha characters followed by five numeric characters.
Semi-Structured and Unstructured documents
Semi-Structured Example – Invoices:
- ICR is required if you want to extract information from invoices, as they are not consistent They share the same document type and index field rules for extraction, but data it is not always in the same place on the page
- Invoices contain an invoice number, invoice date, net, VAT & gross totals, but no two invoices from different suppliers will be the same
- You would therefore setup a rule that would instruct the software to read every word on the entire page and look for keywords such as “Invoice
- Number”, “Document Number”, “Inv No” etc
The software then looks for text in the vicinity of the keywords, usually to the right or underneath and extracts the value.
Example Unstructured – Contracts:
- Contracts generally contain documents of multiple types bundled together. They are usually paper format as they are received by post or fax
- Rules can be defined to classify each document and extract different metadata fields for each type
- If the documents are complex, you can set up a rule that classifies the documents based upon text on the page
- If enough samples are fed in to the system, the software uses self-learned classifiers (it ‘learns as it goes’) to categorise the documents
- The text does not have to be static.
Still not sure? Contact us enquiries@processflows.co.uk or 01962 835053.


ProcessFlows transition to Konica Minolta – FAQ
/in News & Insights /by ProcessFlowsHere is a simple Frequently Asked Questions page to assist you regarding the transfer of ProcessFlows business activities to Konica Minolta Business Solutions (UK) Limited .